

AMA #4: How to estimate the probability of software failure and analyze risk?
In the real world, software does not fail in every use. Yet current standards recommend using a probability value of 1. What is the best approach for analyzing risk of medical software?


Dear colleagues, hello! 👋
Recently, I received the following question:
Your company makes a hypothetical device that treats three conditions, each with a unique workflow A, B, and C. Your data shows that typically users treat patients with these conditions in a ratio of 50%/40%/10% respectively.
Workflow C has a special feature that is used about 10% of the time.
A software defect has been found in the special feature of workflow C.
When calculating probability of occurrence, where you start?
1/1
1/10
1/100
Let us make the following assumptions before analyzing this situation:
All three workflows are part of the same system software. The correct workflow for a condition, and any special features are selected by the user from the device-user interface.
User follows all instructions and there are no use-errors or intentional acts of misuse.
Although the question is about a “software defect”, we do not know the precise nature and cause of this defect. We also do not know the failure trajectory that may include additional defects before manifesting itself at the user interface.
A consequence of the observed software failure is the complete shutdown of the system, which can cause an interruption or delay in treatment of the medical condition.
If left untreated for a significantly long period of time, all three conditions are likely to worsen the patient’s overall health to the same extent.
Although not specified, the probability of occurrence in this question pertains to the probability of occurrence of a hazardous situation resulting from the software failure.
It is important to differentiate between a software failure and a hazardous situation
Before attempting to estimate the probability of a hazardous situation resulting from the software note above, it is important to review a few definitions and an important concept.
According to ISO 149711, there are 3 key terms relevant for this analysis:
Hazard: potential source of harm.
Hazardous situation: circumstance in which people, property or the environment is/are exposed to one or more hazards.
Harm: injury or damage to the health of people, or damage to property or the environment.
One of the most important concept in risk analysis is to understand how an individual risk may be realized in practice to result in harm to people, property or the environment.
According to this concept, an individual risk is associated with a specific hazardous situation, which occurs as a result of a sequence or combination of events following an initial/trigger event. Mere presence of a hazard in a system (i.e. a medical software) is not sufficient; rather it is through a sequence of events that exposure to one or more hazard(s) occurs in a hazardous situation. This exposure is necessary for harm to occur.

As shown in Figure 1 above, there is an added layer of complexity in the sequence of events leading to harm. It is rare that a single, linear sequence of events leads to a specific hazardous situation and a specific harm. In practice, a complex cascade of events may follow the initial occurrence of a hazardous situation, often as a result of an intervention to prevent or mitigate its consequences.
It is a good practice to outline these different scenarios in sufficient detail so that each hazardous situation is linked to only one harm. As a result, there may be multiple hazardous situations and harm pairs associated with a single initial or trigger event. In this way, an individual risk is associated with a unique hazardous situation and harm pair for the purpose of risk analysis.
Probability of occurrence of an individual risk of harm is estimated using the following equation2:

Using the key concept illustrated in Figure 1, P1 can be estimated using the following equation:

Where P(sequence of events) is a combined probability of the chain of events following an initial event that lead to a specific hazardous situation. Individual probabilities of each event in the sequence of events can be combined using the AND and OR rules of probability based on their relationship.
Also note that the initial event may or may not be a software failure, and the sequence of events may include one or more software failures. As an example, a use-error may inadvertently activate a latent defect in the system, leading to a localized fault, that may propagate to a failure at the system level.
Therefore, we should not confuse the probability of occurrence of a software failure with P1.
Let us now understand the link between a software failure and a hazardous situation
First, it is useful to define a few key terms3:
Software defect: an error in design/implementation of the software, often called a “bug”. It may or may not be discoverable.
Software fault: A software condition that causes the software not to perform its intended function. It may or may not be detectable.
Software failure: A software condition that causes the system not to perform as intended. It may or may not be predictable.
Complex software used in medical devices has multiple interrelated elements, each designed to perform a specific operation. An error in one element (i.e. a defect) may remain latent until it is activated by another element, for example, by the information flowing across the two interfaces. A single defect, once activated, may directly result in a fault, or it may trigger a cascade of other defects, indirectly leading to a software fault. These faults may continue to remain latent or cause a failure at the system level under certain conditions.
The relationship between software defect, fault or failure is not always predictable and may not be discovered during initial software validation. As a result, a conservative value of 1 for the probability of software failure is used in the medical device industry4 during the initial design phase.
However, this is not the same as P1, as noted by Bijan Elahi in Chapter 15 of his book, Safety Risk Management, 2nd Edition:
It should be understood that setting P(Software failure ) = 1 doesn’t necessarily mean that P1 = 100%.
If we treat a software failure as the initial or trigger event in Figure 1, the equation for P1 can be updated as:
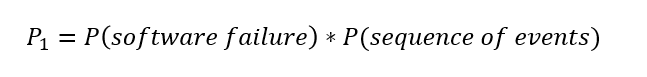
In the case of our hypothetical software medical device, we do not know the specific nature or cause of defect(s) contributing to the observed software failure. Further we cannot rule out the possibility that one or more of these defect(s) involved in the failure trajectory will not cause the software to fail in other workflows.
However, we can conclude that a hazardous situation may not occur in all situations involving a software failure.
There is a difference between predicted and observed probability of software failure
According to the original question, the consequence of software defect(s) is seen only in a special feature of Workflow C, used in about 10% of total applications. Workflow C itself is used only in 10% of patients to treat one of the three medical conditions.

According to the information illustrated in Figure 2 above, we can estimate an observed probability of software failure as 1 in a 100 (= 0.01 or 1%).

Note that we cannot predict the probability of software failure based on a priori knowledge of the software design and testing alone. This is because we do not precisely know the cause and effect relationship between software defect, fault and failure in this case. It is only through post-market information collection and review that we can estimate an observed value for the probability of software failure.
Therefore, it is prudent to use an initial prediction value of 1 for the probability of software failure during the design phase.

This is a conservative approach to analyzing the risk of software failure(s). However, we should emphasize that even with this conservative approach, the probability of occurrence of a hazardous situation (P1) is not necessarily equal to 1 as discussed below.
Let us outline potential sequence of events that may lead to a hazardous situation
According to one of our assumptions, a consequence of the observed software failure is the complete system shutdown, which can cause an interruption or delay in treatment.
As illustrated in Figure 3, in one scenario, an interruption may not lead to a hazardous situation where treatment is delayed by a significant amount of time. In a second scenario, if the user is not able to restore the system, or is not able to find a backup unit, then there may be a significant delay in treatment leading to a hazardous situation.
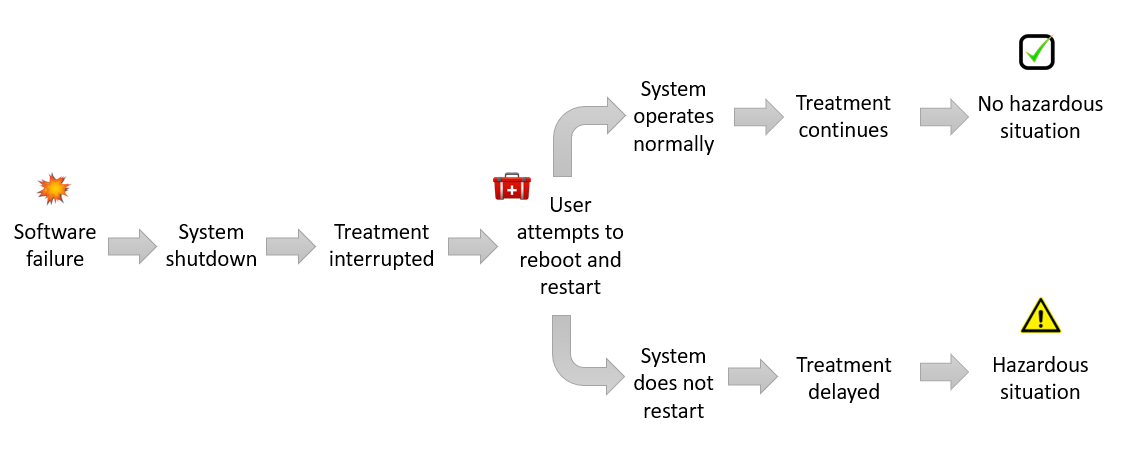
The software failure in this case may be considered a hazard (functionality), and delay in treatment a hazardous situation.
Only one sequence of event in Figure 3 leads to a hazardous situation. If we use a more conservative value of 1 as the probability of software failure, P1 is equal to the combined probability of the appropriate sequence of events:

A highly conservative approach would be to assume that the combined probability of the sequence of events is also 1. In that case, P1 will also be equal to 1.
Let us consider an appropriate level of P2 for analyzing the overall risk of software failure
To the extent possible, we should analyze the risk of software failure as accurately as possible. Both under- and over-estimating risk inherently leads to sub-optimal decisions during design and development.
In this case, it is important to consider if the treatment is time-critical. This may require software engineers to work closely with medical experts who may help establish a threshold for a clinically significant delay in treatment.
If the delay in treatment is significant, then the probability of a hazardous situation leading to harm (P2) is high. If not, then a low P2 value can be used.
Another approach is to consider different P2 values for different harm severity levels that may occur due to a delay in treatment. As an example, a low P2 value can be used for harms of low severity, such as minor inconvenience, temporary and/or reversible symptoms and those requiring no medical or surgical intervention. A higher value of P2 may be used for harms of higher severity, such as those requiring medical or surgical intervention, irreversible and/or life-threatening injury. However, there is no fixed rule or a formula and a distribution of P2 values can be assigned to harms of different severities, ranging from severity of 1 to 5. A rationale for P2 values should be documented based on clinical expertise.
One of our assumptions in this case is that all three conditions, if left untreated for a significant period of time, lead to the same extent of harm for the patient. Therefore, it might be useful to set a clinically significant threshold for delay in treatment, and estimate two different P2 values. Consider the following example:

Note that this is only a hypothetical example, not intended to be used as a general rule. A solid rationale based on clinical input should be documented to support these values for P2. Also note that collectively, the two P2 values should add up to 1. This is because P2 is conditional probability for each hazardous situation.
If we now conservatively set the probability of software failure as 1, we can consider two distinct sequence of events leading to two distinct hazardous situations:
Situation 1: Sequence of events 1 => Clinically significant delay in treatment
Situation 2: Sequence of events 2 => Clinically insignificant delay in treatment
If we assume, with appropriate justification based on data or opinion of subject matter experts (SME), that the two sequence of events noted above would occur with equal probability, then P1 for each of the two hazardous situations will be equal to 0.5.

and;

We now have complete information to estimate the overall probability for occurrence of harm for these two different scenarios.

and;
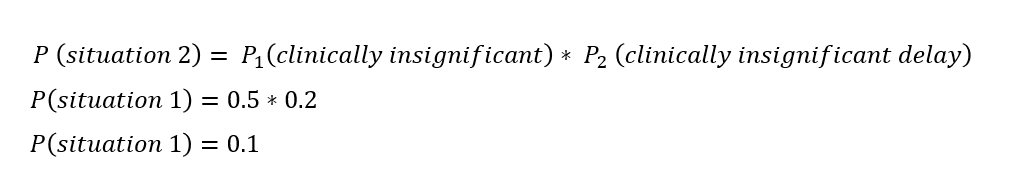
Figure 4 summarizes the overall probability estimates for these two situations:

How to use observed software failure rate data from real world use
As noted in the original question, when data on software failures during real world use is available, we may use it to estimate an observed rate of occurrence. Generally speaking, software does not fail all the time. Therefore, P(software failure, observed) will be lower than the conservative value of P(software failure, predicted) equal to 1 used in the initial design phase.
As a result, it is a good practice to update your risk files with observed rates of occurrence for software failures, and resulting probability values for P1, P2 and the overall risk of harm. You should also adjust your risk acceptability criteria to more accurately reflect the real world experience.
Otherwise, you may not be able to take action when the observed rates of failure change significantly.
In conclusion
A common practice in the medical device industry is to use a conservative value of 1 as the probability of software failure. However, it does not necessarily mean that the probability of a hazardous situation occurring due to a software failure, such as a delay in treatment, is also 1.
This hypothetical case study illustrates the importance of clearly outlining a sequence of events for different scenarios that may follow a software failure. Not all software failures may lead to a clinically significant hazardous situation. Therefore using a highly conservative approach of equating the probability of software failure with the probability of occurrence of a hazardous situation will result in overestimating the risk of harm. Further, an appropriate value for P2, the probability of a hazardous situation leading to harm, should also be considered.
As data from real world use becomes available during the post-market phase, it is a good practice to update the risk files to reflect the observed rate of occurrences and estimated probabilities. It is also recommended to appropriately adjust the risk acceptability criteria to facilitate timely decisions when observed rates of failure change significantly.
Do you find value in this AMA feature? Then consider submitting your own questions. If your question is selected for a future AMA article, you will receive 30-day complimentary access to premium content on Let’s Talk Risk!
ISO 14971: Medical devices - Application of risk management to medical devices (2019 revision).
See Figure C.1 in Annex C of ISO 14971:2019.
Adapted from Chapter 15 in Safety Risk Management, 2nd Edition, by Bijan Elahi.
See IEC 62304: Medical device software - Software life cycle processes.